最近在梳理數(shù)據(jù)生命周期管理的細節(jié)時,發(fā)現(xiàn)了一個小問題���,那就是MySQL的主鍵命名策略,似乎會忽略任何形式的自定義命名��。
也就意味著你給主鍵命名為idx_pk_id這種形式���,在MySQL里面會統(tǒng)一按照PRIMARY來處理���。
當然我們可以在這個基礎之上做一些拓展和補充。
首先來復現(xiàn)下問題�����,我們連接到數(shù)據(jù)庫test,然后創(chuàng)建表test_data2.
mysql> use test
mysql> create table test_data2 (id int ,name varchar(30));
Query OK, 0 rows affected (0.05 sec)
接著創(chuàng)建一個主鍵��,命名為idx_pk_id�,從執(zhí)行情況來看,MySQL是正常處理了�����。
mysql> alter table test_data2 add primary key idx_pk_id(id);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
為了進一步對比��,我們添加一個唯一性索引(輔助索引)�����,來看看它們的差異�����。
mysql> alter table test_data2 add unique key idx_uniq_name(name);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
查看主鍵命名方法1:使用show indexes命令
要查看MySQL索引的信息�����,使用show indexes from test_data2就可以����。
mysql> show indexes from test_data2\G
*************************** 1. row ***************************
Table: test_data2
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: test_data2
Non_unique: 0
Key_name: idx_uniq_name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
查看主鍵命名方法2:使用數(shù)據(jù)字典information_schema.statistics
使用命令的方式不夠通用,我們可以使用數(shù)據(jù)字典information_schema.statistics來進行數(shù)據(jù)提取���。
mysql> select *from information_schema.statistics where table_schema='test' and table_name='test_data2' limit 20 \G
*************************** 1. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: test
TABLE_NAME: test_data2
NON_UNIQUE: 0
INDEX_SCHEMA: test
INDEX_NAME: PRIMARY
SEQ_IN_INDEX: 1
COLUMN_NAME: id
COLLATION: A
CARDINALITY: 0
SUB_PART: NULL
PACKED: NULL
NULLABLE:
INDEX_TYPE: BTREE
COMMENT:
INDEX_COMMENT:
*************************** 2. row ***************************
TABLE_CATALOG: def
TABLE_SCHEMA: test
TABLE_NAME: test_data2
NON_UNIQUE: 0
INDEX_SCHEMA: test
INDEX_NAME: idx_uniq_name
SEQ_IN_INDEX: 1
COLUMN_NAME: name
COLLATION: A
CARDINALITY: 0
SUB_PART: NULL
PACKED: NULL
NULLABLE: YES
INDEX_TYPE: BTREE
COMMENT:
INDEX_COMMENT:
2 rows in set (0.00 sec)
查看主鍵命名方法3:使用show create table 命令
如果查看建表語句����,會發(fā)現(xiàn)主鍵名已經(jīng)被過濾掉了。
mysql> show create table test_data2\G
*************************** 1. row ***************************
Table: test_data2
Create Table: CREATE TABLE `test_data2` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_uniq_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
有的同學可能想�,是不是分別執(zhí)行了create,alter語句導致處理方式有差異,我們可以一步到位�,在create語句里面聲明主鍵名。
CREATE TABLE `test_data3` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY idx_pk_id(`id`),
UNIQUE KEY `idx_uniq_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
這個時候查看建表語句�,會發(fā)現(xiàn)結果和上面一樣,主鍵名都是PRIMARY.
mysql> show create table test_data3\G
*************************** 1. row ***************************
Table: test_data3
Create Table: CREATE TABLE `test_data3` (
`id` int(11) NOT NULL,
`name` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_uniq_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
查看主鍵命名方法4:查看約束命名
當然還有多種驗證方式��,比如我們使用約束的方式來命名�,得到的主鍵名都是PRIMARY.
CREATE TABLE IF NOT EXISTS `default_test` (
`default_test`.`id` SMALLINT NOT NULL AUTO_INCREMENT,
`default_test`.`name` LONGTEXT NOT NULL,
CONSTRAINT `pk_id` PRIMARY KEY (`id`)
);
查看主鍵命名方法5:使用DML報錯信息
當然還有其他多種形式可以驗證�,比如我們使用DML語句����。
mysql> insert into test_data2 values(1,'aa');
Query OK, 1 row affected (0.02 sec)
mysql> insert into test_data2 values(1,'aa');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
以上的方法都可以讓我們對這個細節(jié)有更深入的理解,當然我們可以再深入一些��。
查看主鍵命名方法6:官方文檔
官方文檔里面其實包含了這個信息����,但是不是很明顯��。
關于主鍵的描述����,大體內容如下���,有一條是專門做了聲明��,主鍵名為PRIMARY.
- 一個表只能有一個PRIMARY KEY��。
- PRIMARY KEY的名稱始終為PRIMARY�����,因此不能用作任何其他類型的索引的名稱��。
- 如果您沒有PRIMARY KEY�����,而應用程序要求您在表中提供PRIMARY KEY,則MySQL將返回沒有NULL列的第一個UNIQUE索引作為PRIMARY KEY���。
- 在InnoDB表中�,將PRIMARY KEY保持較短,以最小化輔助索引的存儲開銷����。每個輔助索引條目都包含對應行的主鍵列的副本。
- 在創(chuàng)建的表中�����,首先放置一個PRIMARY KEY�����,然后放置所有UNIQUE索引���,然后放置非唯一索引���,這有助于MySQL優(yōu)化器確定使用哪個索引的優(yōu)先級�����,還可以更快地檢測重復的UNIQUE鍵���。
查看主鍵命名方法7:源代碼
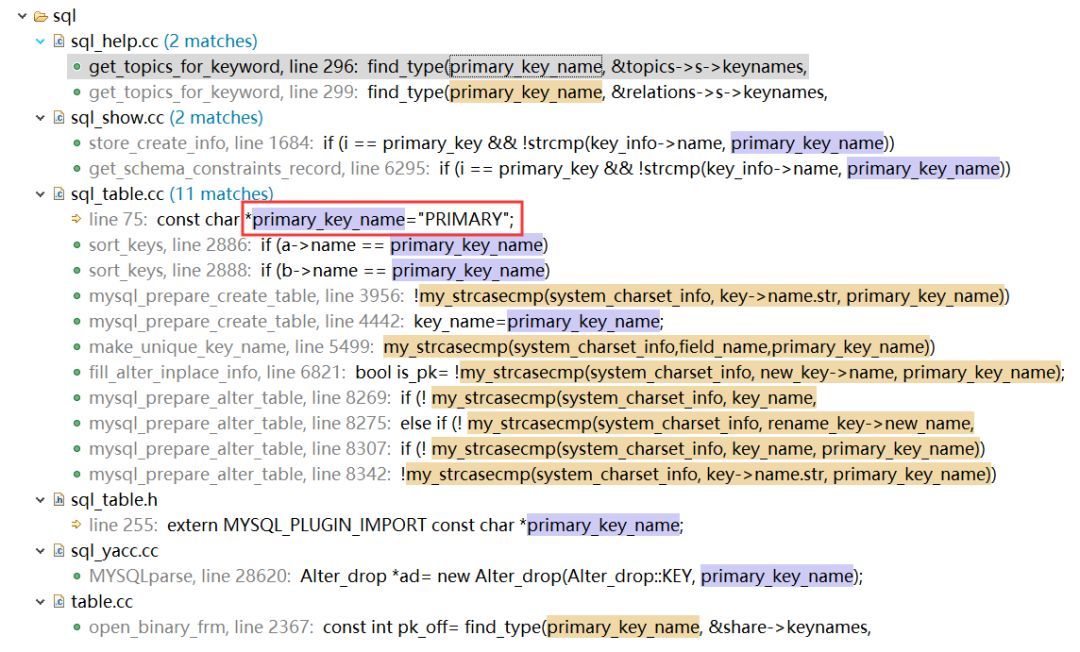
在sql_table.cc 里面對主鍵名稱做了定義聲明����。
const char *primary_key_name="PRIMARY";
順著這條路���,可以看到在不同層的實現(xiàn)中的一些邏輯情況���。
小結:
通過這樣的一些方式����,我們對主鍵的命名情況有了一個整體的認識�����,為什么會采用PRIMARY這樣一個命名呢�,我總結了幾點:
1)統(tǒng)一命名可以理解是一種規(guī)范
2)和唯一性索引能夠區(qū)別開來,比如一個唯一性索引非空��,從屬性上來看很相似的���,通過主鍵命名就可以區(qū)分出來��,在一些特性和索引使用場景中也容易區(qū)分��。
3)主鍵是一個表索引的第一個位置��,統(tǒng)一命名可以在邏輯判斷中更加清晰���,包括字段升級為主鍵的場景等等。
4)在優(yōu)化器處理中也會更加方便�����,提高MySQL優(yōu)化器確定使用哪個索引的優(yōu)先級���。
以上就是MySQL的主鍵命名策略相關的詳細內容����,更多關于MySQL 主鍵命名策略的資料請關注腳本之家其它相關文章�����!
您可能感興趣的文章:- 深入談談MySQL中的自增主鍵
- Mysql主鍵UUID和自增主鍵的區(qū)別及優(yōu)劣分析
- 淺談MySQL中的自增主鍵用完了怎么辦
- MySQL的自增ID(主鍵) 用完了的解決方法
- 深入分析mysql為什么不推薦使用uuid或者雪花id作為主鍵
- 詳解MySQL 表中非主鍵列溢出情況監(jiān)控
- 使用prometheus統(tǒng)計MySQL自增主鍵的剩余可用百分比
- Mysql 增加主鍵或者修改主鍵的sql語句操作
